
Introduction
Working on a side training project and improving the way I build with coding agents with the idea for better orchestrating, tracking and auditing agents work.
I attended a Microsoft spec-driven “spek-kit” demo call where they discussed how to better organize these agents with the goal to make them more predictable.
Buried beneath that marketing fluff, they did touch on key design principles which were grounded on architecture and design planning and mature product development and requirements management.
At first, I thought this was going to be another AI fad and die out, but after a month of hallucinations and poor AI grounding, I decided to give it a go. The practices seemed anchored to clear requirements, scoped slices of functionality and documented decisions rather than vague prompts alone. And I was so frustrated with trying to engineer explicitly prompts, skills, and spreadsheets for requirements that I decided to give it go.
Honestly, it seems better, if any steering guiding and direction can stay grounded in the feature slices, bugs and fixes. But even so, I found that the agent can veer off course with one bad prompt, correction or bug …
What I’m Doing Today
At a practical level, I started with a taxonomy that grounds and structures all future AI Agent work. This does require some planning and critical thinking. This is foundational and if the foundation is not strong then the AI Agent will diverge from the intent or make unwise performance decision, poor operational decisions or fail to consider disaster recovery architecture.
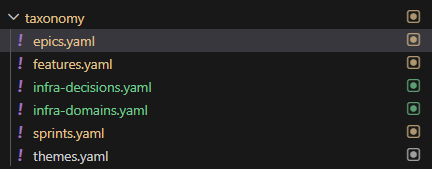
Portfolio and Planning Structure
- Every major initiative starts with an Epic and Epic ID
- Each epic maps to one or more Sprints
- Each sprints may span one or more Features
- Features are then broken into feature slices which are more manageable for the agent
- Multiple sprints can contribute to the same feature or slice, which makes progress easier to track without losing the original intent
This mirrors established agile practice where large bodies of work are decomposed into smaller units for planning and execution.
I went back and forth on this, because technically AI agents don’t need to understand human concepts, but I thought this would be a clean map to git commits, PRs and traceability back to Jira tickets.
Requirements and Traceability
- Each feature slice is tied back to:
- Requirements
- Acceptance criteria
- Sprint status
- Implementation history
- This creates a traceability model so I can move from requirement to slice, from slice to code change and from code change back to scope.
The idea at least, is this makes formal requirements management easier. The traceability exists to help AI Agents understand upstream and downstream impact, validate coverage and keep implementation aligned with design intent.
What I found, is that as the management aspect of this approach grows, you also need special skills to “manage” your work much like you need agent skills to write code or build a database schema. Otherwise, an agent can still go rogue.

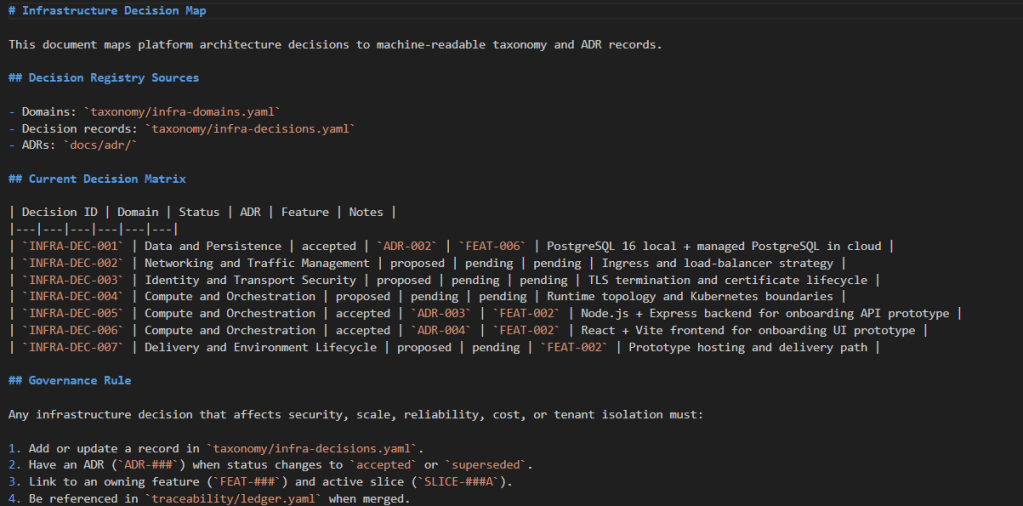
Infrastructure Decision Tracking
Over the year playing with coding agents, I found that they got better at pumping out script but they lost context of the underlying hosting environment and infra dependencies. So, as implementation evolves within the project, infrastructure choices are recorded in a dedicated infrastructure decisions template.
That includes decisions such as:
- Node.js
- React
- Vite
- PostgreSQL
- Kubernetes
- Package Dependencies
Each decision is documented so it can be mapped back to the relevant feature slices. This is heavily inspired by the idea behind lightweight architecture decision records. Capture important technical decisions, their context and their consequences in a way that future contributors can understand. I found too many times, I was losing this along the way which made it difficult to recover for hallucinations and crashed agent tasks.
Additionally, this also helped me plan for different agents and different kills that I’d need for different engineering phases of the protype.
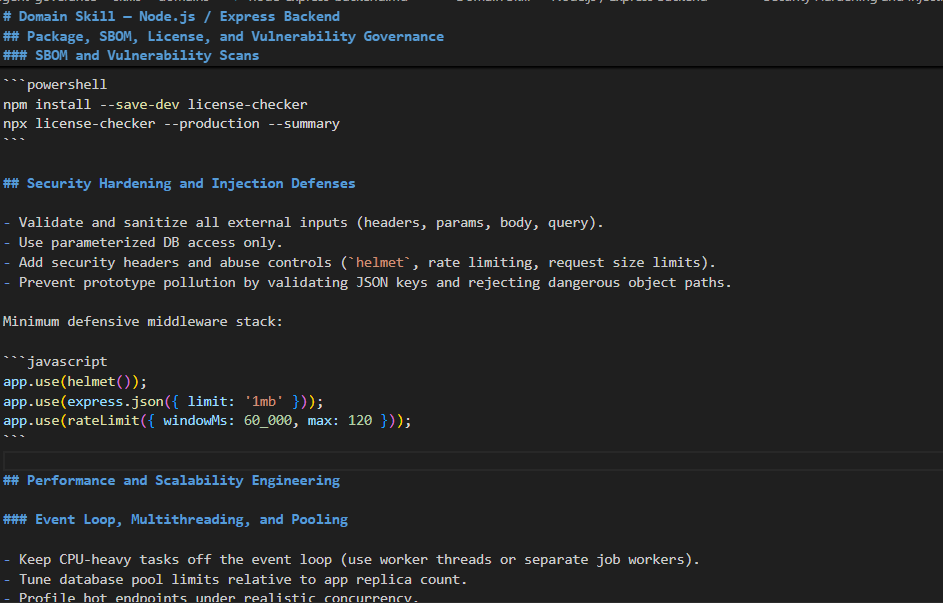
Skills for Agents
For every feature slice, I also map the agent to the right support skills, including:
- Database schema design
- Debugging assistance
- Architecture support
- security analysis
This matters because security and engineering concerns often need to be handled explicitly at the story and acceptance-criteria level, not bolted on at the end.
Thoughtworks’ guidance on agile threat modeling makes the same point that security work can and should be expressed through stories, acceptance criteria, spikes and definition-of-done updates.

How the Agent Is “Governed”
Agents.md and Execution Rules
My Agents.md file points to a set of execution rules that govern how agents should work. Those rules define:
- When to consult specific skills
- How to interpret feature slices
- How to use acceptance criteria
- How to respect infrastructure domain decisions
Skill Consultation Guide
I also maintain a skills consultation guide that helps the agent determine which skill to use based on:
- feature
- slice
- acceptance criteria
- infrastructure domain
Delivery
Beyond coding itself, each agent is expected to maintain disciplined execution hygiene.
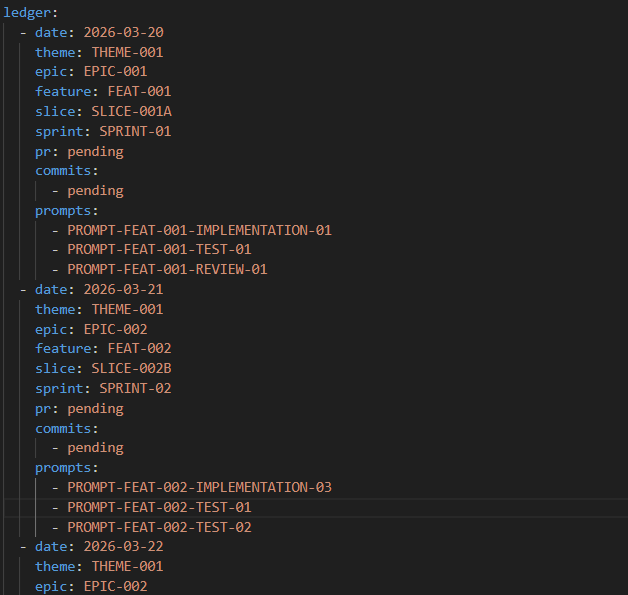
Delivery Skills
- Regular Git commits
- Versioned changes
- Clear mapping between work and scope
- Running ledger of
- sprint
- feature slice
- date
- related changes
This ledger acts as a practical cross-reference, so I can trace work back to requirements, scope movement, and commit history.
In other words, the agent is not just writing code but also contributing to a system of accountable delivery.
Early Results
After only a few days of prototyping, the improvement has been noticeable.
What improved
- Hallucinations dropped from roughly 3–4 per hour to almost none,
- the need for constant steering fell from roughly hourly intervention to minimal intervention
- Security bugs plus poor commit-history practices dropped by about 80%.
These are my own early observations rather than formal benchmark results, but once agents are grounded in structured requirements, traceable slices, explicit decision records and governed execution rules, they appear to become far more reliable.
What I’m seeing is that coding agents perform much better when they are treated less like improvisational assistants and more like participants in a disciplined engineering system.
However a bug or the addition of a a missing feature slice is still enough to take the agent off course. Steering in a new direction can result in the agent not tracking its work and not updating feature slices, change records and using. Something else needs to be added, like a “manager” agent or “governing” agent which reviews the work, the benchmark and ensures completion and accuracy.
Lessons Learned So Far
What seems to matter more is giving the agent:
- Stable taxonomy
- Explicit traceability
- Scoped feature slices
- Documented infrastructure decisions
- Skill-routing rules
- Delivery discipline tied to version control
That combination appears to reduce ambiguity, narrow the solution space and improve both technical quality and security posture.
Closing Thoughts
I’m still early in this experiment but so far the results are encouraging.
Especially when it comes to wrapping clearly defined source code security analysis and security feature development and testing.
The more I apply principles from requirements management, traceability, architecture decision recording and acceptance-criteria-driven delivery, then the more my agents behave like disciplined contributors instead of talented but chaotic improvisers guided by an insane vibe coding end-user.

References
- Fowler, M. (2013, April 22). User story. MartinFowler.com.
- IBM. (n.d.). DOORS: Linking and traceability. IBM Documentation.
- IBM. (n.d.). What is requirements management? IBM.
- Palmer, J. D. (2002, September). The role of requirements traceability in system development. IBM Rational Edge.
- Thoughtworks. (2016, November 7). Lightweight architecture decision records. Thoughtworks Technology Radar.
- Thoughtworks. (2025, May 20). Threat modeling guide for software teams. MartinFowler.com.
