This article is about the uncomfortable truth that AI coding agents do and will continue to be used to write mission critical security code in products. Both now and in the future. And whether you like it or not and as much as I scrutinize prompt injection and over permissive agents, we need learn to co-exist with coding agents and build systems with then that get better over time. This isn’t me championing and condoning AI agents for critical code, but instead it’s my being open minded and simply exploring “what if” we wanted to use them could we do it better …
So, you open Cursor. You type: “add SSO and multi-tenant RBAC to this app.”
The agent runs. Files appear. It looks… pretty good actually.
- JWT middleware? Check.
- Password hashing? Check.
- Some kind of role check on the admin routes?
Yep. It works. You ship it.

Six months later, a tenant calls you. Their data is leaking into another tenant’s workspace. You stare at the logs. The token is perfectly valid. Signed correctly. Not expired. And it’s reading data from an org it has absolutely no business touching.
Congrats. Your AI agent just reproduced one of the most common auth vulnerabilities in the wild, wrapped in clean TypeScript, with zero test coverage for the attack surface.
Because you never told it about the attack surface. And here’s the part that’s harder to say out loud, you didn’t tell it because you didn’t know it needed telling.
That’s what this post is really about.
The Dunning-Kruger Accelerator: When the Model Knows More Than You Do About the Wrong Things
Auth and IAM are genuinely hard domains. They require knowing not just how to implement a JWT library call, but why the audience claim exists, what a confused deputy attack is, what PKCE prevents and why it matters even for confidential clients, and what the difference is between a security check at provisioning time versus a security check at every login.
Most developers, even good ones, don’t have deep fluency in all of these concepts. That’s not a character flaw. It’s just a specialized subdomain that most people don’t need until they suddenly do.
I’m even experiencing some Dunning-Kruger effect myself writing this article … even the act of sitting here, testing my coding agent and researching Oasis and OIDC helped me know what I don’t know …
The problem is what happens when someone who doesn’t have that fluency sits down with an AI agent to build a multi-tenant auth system. Someone who isn’t even aware of what they don’t know. An overly confident new developer being coerced by an overly optimistic positive re-enforcing coding agent.
The model doesn’t ask: “Before we start, do you understand audience claim validation? Do you know what a confused deputy attack is? Are you aware of SAML XML Signature Wrapping?”
So you we this:
✅ Congrts! I've implemented JWT authentication for your multi-tenant app! The middlewareverifies the token signature using your public key and extracts the user ID fromthe `sub` claim. The role-based middleware checks against your tenant'sconfigured roles. Everything looks good — want me to add refresh token support?
Green checkmarks. Positive framing. “Everything looks good.”
The user reads this and thinks…. great, auth is done. All the while, they don’t know what they don’t know.
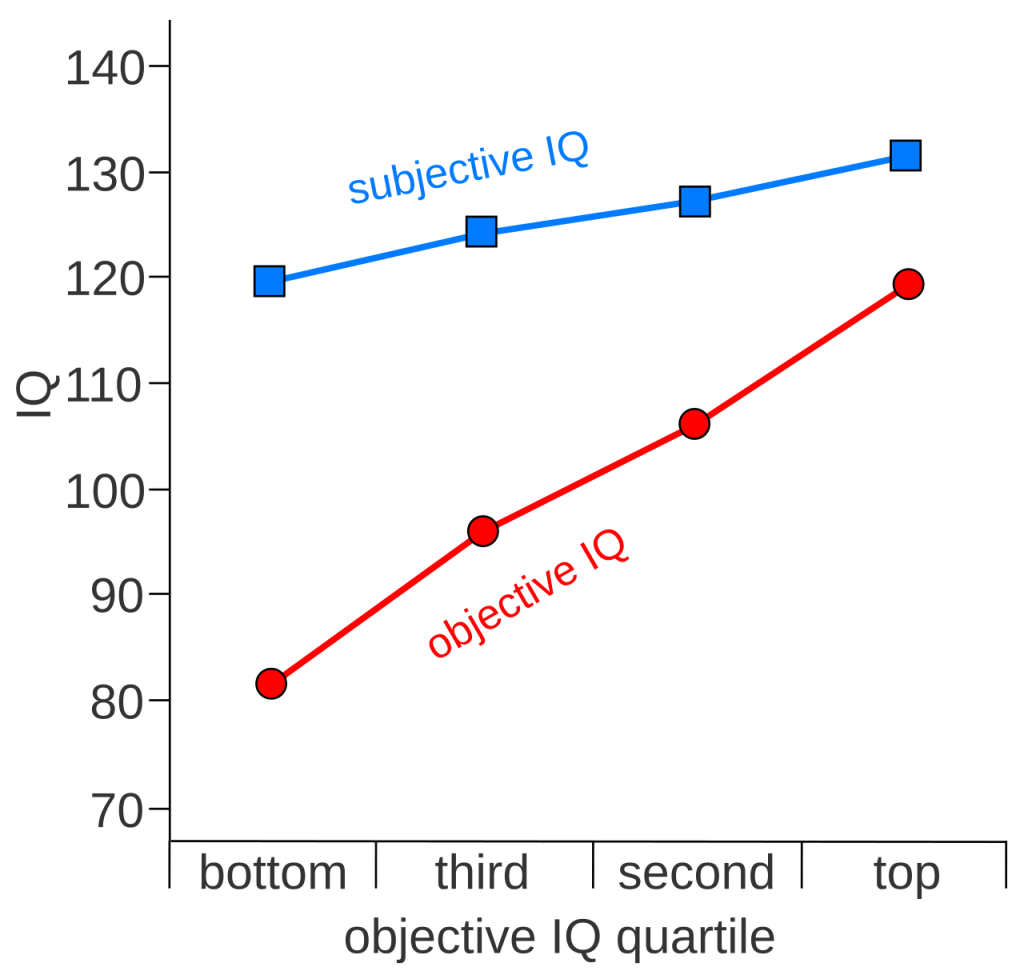
A Stanford Human-Computer Interaction group studied exactly this dynamic. Their 2023 research found that participants using AI code assistants wrote significantly less secure code than those working without AI and simultaneously were more likely to rate their insecure code as secure.
A Snyk survey of developers and practitioners found that nearly 80% believed AI-generated code was more secure than code they’d write themselves. That belief is not supported by the evidence. It’s a product of confident presentation style.
And if you don’t know enough about IAM to even formulate the right question, you will never get the right answer. The model will just keep saying “✅ looks good!” all the way to production.
It’s The Agent + What Humans Ask It To Do.
With all that context sitting on the table, let’s get into the actual auth problems.
When you ask an agent to implement JWT validation, you get this:
// Looks fine. Isn't.async function validateToken(token: string) { const payload = jwt.verify(token, getPublicKey()); return { valid: true, userId: payload.sub };}
Signature verified. Expiry checked. Done, right?
Nope. Nobody checked the aud claim. Nobody verified the iss matches this tenant’s IdP config. So a user in Tenant A can take their completely valid, correctly-signed JWT, point it at Tenant B’s API endpoint and the request sails right through.
This is called a confused deputy attack. It’s not new or AI specific. It’s not a zero-day. It’s just a missing three-line validation that every tutorial skips because the tutorial doesn’t have tenants.
Your agent isn’t dumb. It’s under-informed. Big difference.

Other IAM Topics Agents + Humans Get Wrong
Beyond the confused deputy problem, here’s what I’m seeing in agent-generated auth code for multi-tenant systems ….
The flat user table. Agent creates a users table with a tenant_id foreign key. Looks right. Isn’t. There’s no UNIQUE(tenant_id, email) constraint.
- No Row-Level Security.
- No query-layer enforcement.
- One developer forgets a
WHERE tenant_id = $1on a single endpoint and you have a cross-tenant data leak. In a codebase with 200 endpoints, someone is going to forget.
Hardcoded credentials. The agent write code to integrate your third-party IdP. It puts the client secret directly in the service file. It’s how every tutorial shows it. GitGuardian measured it. The repos with Copilot active have a 40% higher secret leak rate. This is not a coincidence.
Missing Authn/AuthZ controller on early APIs. Some early developed API endpoint before the auth feature was introduced is skipped, accepts the request from literally anyone who’s authenticated.
No audit log from day one. The agent builds a working system. The audit log gets added “later.” Later means there’s a gap.
Group claim confusion across tenants. Tenant A and Tenant B both have an IdP group called “Administrators.” Both map to tenant_admin. A logic bug in the mapping lookup — using group name as the key instead of (tenant_id, idp_config_id, group_name) — and Tenant A’s admin just got access to Tenant B. The agent wrote the query. Nobody told it this was a compound key problem.
Stop Asking for Code. Start Giving Specs.

We’re handing the agent a job description when you should be handing it a threat model.
“Add JWT validation” is a job description.
“Implement token validation that mitigates T-F001 cross-tenant token confusion per OpenID Connect Core §3.1.3.7, with atomic iss+aud+exp+jti checking, rejecting any token where aud does not exactly match this tenant’s registered client_id, and emitting an audit event on every validation failure” — that’s a spec.
Here’s a framework I’m playing with to improve IAM development features. Four layers. All of them live in the repo. All of them are machine-readable.
The four layers
1. Attack-vector + threat tacebility matrix 2. Threat model docs one markdown file per threat, MUST/MUST NOT blocks, RFC citations3. Feature slices work units explicitly tagged with the threat IDs and Vtor ID they mitigate3. Skill files reusable agent context docs with domain expertise and constraints4. Attack-vector unit tests named after what they prevent, not what they test, mapped to Featire Clises and THreat IDs5 Bug Report matrix and status that feeds back into threats, vectors and features/slices
Layer 1: Threat Model as Machine-Readable Spec
A threat model locked in Confluence is useless to your agent. A threat model in a structured markdown file that lives at /docs/threat-model/ is part of my daily context window that steers new developed auth code and test cases.
The key is the MUST / MUST NOT structure. Those become your acceptance criteria and your agent’s constraints simultaneously.
# /docs/threat-model/T-F001-cross-tenant-token-confusion.md## T-F001: Cross-Tenant Token Confusion (Confused Deputy)Risk: CRITICAL | Likelihood: HIGH | Mitigates: SLICE-007B### The attackAttacker holds a valid token with `aud: "client-tenant-a"` and sends it to`GET /tenants/tenant-b/workspaces`. Signature-only validation passes.Attacker reads tenant-b's data. Classic confused deputy.### Implementation MUST- Validate `iss` AND `aud` atomically — partial pass is a full fail- Reject if `aud` does not exactly match the tenant's registered `client_id`- Extract tenant context from the JWT only. Never from URL params.- Log every failure: tenant_id_requested, aud_in_token, iss_in_token, path### Implementation MUST NOT- Accept tokens where `aud` is absent or is a wildcard- Short-circuit if `iss` matches but `aud` does not- Cache validation results across different tenant contexts### References- RFC 7519 §4.1.3 (aud): https://datatracker.ietf.org/doc/html/rfc7519#section-4.1.3- OIDC Core §3.1.3.7: https://openid.net/specs/openid-connect-core-1_0.html- Real-world: https://sec.okta.com/articles/2023/08/cross-tenant-impersonation...
The references matter as much as the MUST blocks. When you tell the agent to read RFC 7519 §4.1.3 before writing any code, it reasons from the spec instead of from pattern-matched training data. Georgetown CSET’s analysis found that LLMs trained on functionality benchmarks produce dramatically different output when the prompt includes authoritative constraints.
The spec is the constraint.
Core references for every auth context:
| Concern | Reference | Why it matters |
|---|---|---|
| Token claims | RFC 7519 — JWT | iss, aud, exp, jti |
| OAuth flows | RFC 7636 — PKCE | Code injection prevention |
| OAuth security | RFC 9700 — OAuth BCP | Current attack mitigations |
| OIDC validation | OIDC Core 1.0 | nonce, issuer, ID token order |
| SAML | OWASP SAML Cheat Sheet | XSW variants, validation order |
| Access control | OWASP A01:2025 | PEP, IDOR, escalation |
Layer 2: Feature Slices Focused on What They’re Protecting
A feature slice is a vertical cut through the system with schema, service, endpoint, tests for one coherent unit of work. The key addition is making each slice explicitly trace back to the threat IDs it mitigates.
When a developer (or an agent) opens a slice, they immediately know what attacks this code is supposed to stop. When you’re reviewing agent output, you’re checking against a checklist, not vibing whether it feels secure.
# /docs/slices/SLICE-007B-token-validation.md## SLICE-007B: Token Validation EngineMitigates: T-F001 (confused deputy), T-F005 (replay), T-F010 (JWKS cache poisoning)Depends on: SLICE-007A (IdP config), SLICE-001 (audit log)Schema- `tenant_jwks_cache` (tenant_id, kid, public_key, fetched_at, expires_at)- `used_jti_claims` (jti, tenant_id, used_at) — append-only, TTL 24hService: TokenValidationService- `validateIdToken(token, ctx)` — atomic iss+aud+exp+jti, no short-circuits- `refreshJwks(tenantId)` — rate-limited, kid-tracked, TLS only- `isJtiUsed(jti, tenantId)` — O(1) lookup against used_jti_claimsTests (named after threat IDs)- /tests/security/T-F001-cross-tenant-confusion.test.ts- /tests/security/T-F005-token-replay.test.ts- /tests/security/T-F010-jwks-cache.test.tsSlice ordering matters. You cannot build secure authorization on an insecure identity foundation.Phase 0 — before anything else: Tenant data model with RLS, append-only audit log, break-glass accounts. That audit log especially. If it's not there from day one, you have gaps. Gaps are where investigations die.Phase 1 — local auth: Local credentials, signed bearer tokens for authorization extensible to future features, sessions, basic RBAC with a real Policy Enforcement Point. Not hidden buttons. An actual server-side policy enforcement check check. MFA Totp required on local accounts. Phase 2 — federation: IdP config management, token validation engine, PKCE/OAuth flow.Phase 3 — hardening: SAML XSW protection, JIT provisioning with group sync on every login, policy-based RBAC.Phase 0 is non-negotiable and almost always skipped. Everyone starts at Phase 2. Then they wonder why there's no paper trail when something goes wrong.
Layer 3: Skill Files — Domain Expertise the Agent Can Read
A skill file is a reusable system prompt you write once and include in every agent context that touches a specific security domain.
Think of it as a security senior engineer sitting next to the agent for that task one who never gets tired, never skips the edge cases, and doesn’t use positive reinforcement to make you feel better about a missing aud claim.
You actually need to know, you need these skills, before you use them or define them. And you also need to know, when to update them and improve them with lessons learned. Like human would…
# /ai/skills/oidc-token-validation.mdYou are implementing ID token validation for a multi-tenant SaaS platform.Mitigates: T-F001, T-F005, T-F010.Validation order — follow exactly (OIDC Core §3.1.3.7)1. Get signing key by `kid` from tenant's JWKS cache2. Verify the cryptographic signature3. Verify `iss` exactly matches `tenant.idpConfig.issuer`4. Verify `aud` contains exactly `tenant.idpConfig.clientId` — partial match = FAIL5. Verify `exp` has not passed (max 300s clock skew)6. Verify `iat` is not in the future7. Verify `jti` has not been used before8. Verify `nonce` if this is an authorization code flowMUST NOT- Accept `alg: "none"`- Accept missing, absent, or wildcard `aud`- Fetch JWKS on every request — cache it; refresh only on unknown `kid`- Reuse validation results across tenant contexts- Let any validation failure pass silently — every failure = audit event- Accept anything outside RS256, ES256, PS256- Hardcode client secrets or signing keys — use environment variables via a secrets managerAudit event on every failure{ event: "token_validation_failed", tenantId, reason, tokenIss, tokenAud, tokenKid, requestPath }# /ai/skills/authorization-middleware.mdYou are implementing the Policy Enforcement Point for a multi-tenant platform.Mitigates: T-001 (missing PEP), T-002 (vertical escalation), T-006 (self-modification).Default denyNo matching policy for (actor, action, resource) = DENY and LOG.A missing policy is not an error. It is a denial.Tenant context- tenant_id comes from req.auth.tenantId only- NEVER read from req.params, req.query, or req.body- If URL slug doesn't match JWT tenant_id → 403, alwaysSelf-modification block (T-006)For any role or permission change:- Verify actor.id !== target.userId before proceeding- If actor === target → 403, reason: "self_modification_blocked"- Log: { event: "self_modification_attempt", actorId, targetId, action }Every endpoint must declare its policyUndeclared endpoint = build failure. No exceptions.The reusable prompt that ties it all together:Read /ai/skills/oidc-token-validation.md and /docs/threat-model/T-F001.mdbefore writing any code.Implement TokenValidationService.validateIdToken() in/src/auth/token-validation.service.tsAfter implementing, generate unit tests in/tests/security/T-F001-cross-tenant-confusion.test.tsusing the attack scenarios from the threat model file.You're not asking for JWT validation. You're asking for an implementation of a specification. The output is now verifiable against the spec. That's the whole point.
Layer 4: Unit Tests Named After the Attack They Prevent
Name your security tests after the threat ID and the attack, not the function.
// T-F001-cross-tenant-confusion.test.tsdescribe("T-F001: Cross-Tenant Token Confusion", () => { it("MUST reject a valid token presented to the wrong tenant", async () => { const token = signTestToken({ aud: "client-tenant-a" }); const ctx = { tenantId: "tenant-b", clientId: "client-tenant-b" }; const result = await svc.validateIdToken(token, ctx); expect(result.valid).toBe(false); expect(result.reason).toBe("audience_mismatch"); }); it("MUST emit an audit event on audience mismatch", async () => { await svc.validateIdToken(token, wrongTenantCtx); expect(auditLog).toContainEvent({ event: "token_validation_failed", reason: "audience_mismatch" }); }); it("MUST NOT accept a token where aud is absent", async () => { const token = signTestToken({ sub: "user-1" }); // no aud const result = await svc.validateIdToken(token, validCtx); expect(result.valid).toBe(false); expect(result.reason).toBe("missing_audience"); });});// T-F005-token-replay.test.tsdescribe("T-F005: Token Replay Attack", () => { it("MUST reject a token whose jti was already used", async () => { await jtiStore.markUsed("jti-123", "tenant-a"); const token = signTestToken({ jti: "jti-123" }); const result = await svc.validateIdToken(token, validCtx); expect(result.valid).toBe(false); expect(result.reason).toBe("jti_replay"); });});// T-F006-saml-signature-wrapping.test.tsdescribe("T-F006: SAML Signature Wrapping (XSW)", () => { it("MUST reject a SAML response with multiple Assertion elements", async () => { const malicious = loadXswFixture("xsw-v1-duplicate-assertion.xml"); const result = await samlSvc.validateAssertion(malicious, tenantConfig); expect(result.valid).toBe(false); expect(result.reason).toMatch(/multiple_assertions|schema_violation/); }); it("MUST verify signature before reading assertion content", async () => { const order: string[] = []; jest.spyOn(samlSvc, "verifySignature").mockImplementation(async () => { order.push("sig"); return true; }); jest.spyOn(samlSvc, "extractClaims").mockImplementation(async () => { order.push("claims"); return {}; }); await samlSvc.validateAssertion(validXml, tenantConfig); expect(order[0]).toBe("sig"); });});// T-006-self-modification.test.tsdescribe("T-006: Self-Modification Attack", () => { it("MUST block a user assigning a role to themselves", async () => { const result = await rbac.assignRole({ actorId: "user-123", targetUserId: "user-123", roleId: "tenant_admin", tenantId: "tenant-a", }); expect(result.allowed).toBe(false); expect(result.reason).toBe("self_modification_blocked"); });});
When an Agentic CICD runs these and they pass, you have some early evidence that those attack vectors are mitigated. When a future developer changes the validation logic and one of these breaks, they’ll know what attack they just re-introduced.
Then compliment this approach with a secondary or even third agent specially trained on security penetration testing, static code analysis. Then finish it off with some good ol’ fashion human in the loop.
Current Project Structure (Pseudo’ish)
project/├── docs/threat-model/ # one file per threat, MUST/MUST NOT blocks│ ├── T-F001-cross-tenant-token-confusion.md│ ├── T-F005-token-replay.md│ ├── T-F006-saml-signature-wrapping.md│ └── T-F013-jit-provisioning-escalation.md├── docs/slices/ # each slice tags its threat IDs│ ├── SLICE-001-tenant-model-rls.md│ ├── SLICE-002-audit-log.md # build this first, always│ ├── SLICE-007B-token-validation.md # mitigates T-F001, T-F005, T-F010│ └── SLICE-007D-saml-validation.md # mitigates T-F006, T-F007├── ai/skills/ # include in every auth prompt│ ├── oidc-token-validation.md│ ├── saml-assertion-validation.md│ ├── authorization-middleware.md│ ├── tenant-scoped-repository.md│ └── audit-log-emission.md├── ai/prompts/│ └── implement-slice.md└── tests/security/ # named after threat IDs├── T-F001-cross-tenant-confusion.test.ts├── T-F005-token-replay.test.ts├── T-F006-saml-xsw.test.ts├── T-F009-group-claim-confusion.test.ts├── T-F013-jit-provisioning-escalation.test.ts├── T-001-missing-pep.test.ts└── T-006-self-modification.test.ts
The ai/ directory is the thing that makes your security requirements legible to the agent.
The audit-log-emission.md skill goes into every implementation prompt ensuring audit events are emitted consistently whether the agent is working on token validation or group mapping or break-glass account logic.
So What?
The result has been impressive so far. While I don’t fully trust the code that has been drafted by this spec-driven framework because it will not account for human social engineering and may have confirmation bias built into the self drafted test, I do think it is more organized, provides better coverage and is grounded in working group best practices and references.
So after v.0001 of this product I’ll likely move onto building an agent with performs simple Owasp Zapp Web Application tests, brute forcing password attacks, sql-injection and no-sql injection attacks and attempts to construct legitimate tokens and then malform them in various combinations and permutations. And even then… I trust it the same as an automated SAST test… if it’s high risk and worth it then it’s worth having some paranoid and creative humans try to break it.
The more insidious problem is the one Stanford researched, that developers using AI assistance not only wrote less secure code, they were more confident it was secure. The model said “✅ looks good!” The developer believed it. The human was i the loop but nobody in that loop knew what wasn’t being checked.
I’m using the spec-driven approach as a response to that problem. While not a silver bullet, the threat model docs tell the agent what to check, what threats to consider and grounds it in a traceable taxonomy. Then layering other Agents at systematic phases as though humans are collaborating sharing skills and ideas, idea for a collective “id” or autonomous collective. Compared to a random guess, a misquoted prompt, I think it’s better … by how much, I’m not sure…
The MUST NOT blocks help reduce the confident-but-wrong shortcuts. The attack-named tests create a CI gate that doesn’t care how positive the agent’s output description was, it only cares whether the audience mismatch returns a rejection and emits an audit event.
The intention, although blind hope, is that my agent will write exactly as secure a system as the specification, I give it. When it comes time to turn it over for additional scrutiny or review, hopefully it performed equally or better than a few developers without security training. Give it nothing, get tutorial code.
References
- Okta Security: Cross-Tenant Impersonation Prevention and Detection (2023)
- Obsidian Security: Behind the Breach — Cross-Tenant Impersonation in Okta
- Veracode: 2025 GenAI Code Security Report
- Stanford HCI: Do Users Write More Insecure Code with AI Assistants? (Perry et al., 2023)
- Georgetown CSET: Cybersecurity Risks of AI-Generated Code (November 2024)
- Security Degradation in Iterative AI Code Generation (arXiv, 2025)
- AI Agents Don’t Understand Secrets — GitGuardian data, CVE-2025-68664, CVE-2025-3248
- Pillar Security: Rules File Backdoor — Cursor and GitHub Copilot (March 2025)
- Apiiro: 4x Velocity, 10x Vulnerabilities (September 2025)
- The Register: Using AI to code does not mean your code is more secure (March 2026)
- RFC 7519 — JSON Web Token (JWT)
- RFC 7636 — PKCE for OAuth 2.0
- RFC 9700 — OAuth 2.0 Security Best Current Practice
- OpenID Connect Core 1.0 §3.1.3.7 — ID Token Validation
- OWASP SAML Security Cheat Sheet
- OWASP Top 10:2025 — A01 Broken Access Control
